Special Uses with Compare¶
This section describes how to make a matrix listing for Interdyme using Compare, and how to make tables using Dirfor files.
Using Compare as a Matrix Lister for Interdyme
A “matrix listing” displays all of the cells in a row or column of an input-output table. The command in the stub file simply is the following.
\matlist <sectors>
For example, it could be
\matlist 1 5 7 15-30 (21 23-25)
where we have used the now-familiar system of indicating a list of sectors.
Two related commands should the \matlist command: \row or \column and \cutoff. Here is a complete example of a stub file for a matrix listing:
\date 1987 1988 1989 1991 1993 1995 2000 1991-1995 1990-2000 1995-2000
\ti MUDAN MATRIX LISTING
\9 1 66 1 3 33
\row
\cutoff 0.02
\matlist 18-25
This will produce a row listing; a cell of a matrix must account for at least 0.02 of the total (two percent of the row total) in order to be listed. Rows 18 - 25 will be listed.
The \matlist command causes Compare to look for a file which at present must be called “MATLIST.CFG”. Here is an example from Mudan.
In this file, all lines beginning with a ‘#’ are comments, and anything before a ‘;’ on a line is also a comment. The first line that does not begin with a ‘#’ must be the matrix listing identity. It specifies an input-output identity in terms of the particular model. Usually this identity says, in effect, total output = intermediate demand plus final demand, but other identites are possible. The identity must have a single vector on the left and then on the right an expression that is the sum of a number of terms. Each term may be either a single vector, like cr and cu in the example, or may be a matrix*vector product, such as am*out and bmv*capital. The terms should be joined by + or - signs. The matrix*vector terms result in a display of all flows obtained by multiplying each column of the matrix by the corresponding element of the vector.
Following the identity, the next non-comment line must provide the title file name for the vector on the left hand side of the identity. The file name must be enclosed in quotation marks (“”). These title files can be the same one used with G7 but Compare skips the 10-letter abbreviation at the beginning of each line which is used by the G7 show command. Rather, Compare looks for a string within “ marks, and uses that. Other material may be in front of or after the quoted string. Here are the first few lines of the sectors.ttl file used in the above example.
Agricul ;1 e "Agriculture"
Coal ;2 e "Coal"
CrudeOil ;3 e "Crude Oil & Natural Gas"
There also must be file names for the titles of the columns of every matrix in a row listing or the row of every matrix in a column listing. In the example they are SECTORS.TTL and BMV.TTL. These files should be of the form as just explained with the titles between quotes.
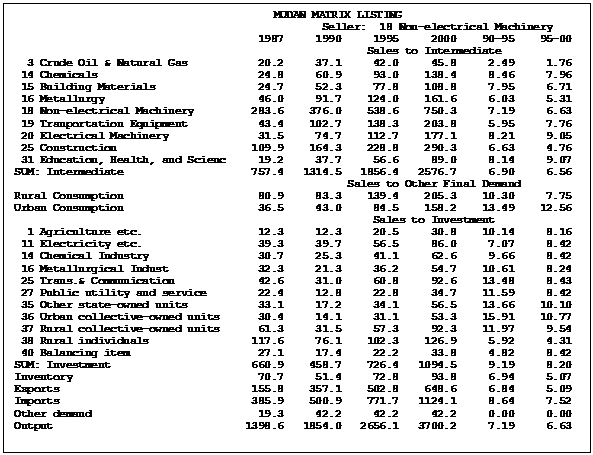
Finally, for each term in the identity, MATLIST.CFG must show the name to be listed with the term. These term names also are shown as strings within quotes. For a vector term, this name will be listed on the left. For a matrix*vector term, it will be centered above the display of the cells of the matrix. The box below shows a sample of the matrix listing produced by our example.
Using Dirfor Files with Compare
Although Compare primarily was developed for use with G7 and Interdyme, it also can be used with the DIRFOR files that traditionally are created by the LIFT and SLIMFORP software. This section will illustrate what needed to be done to get the Dirfor files for the Japanese model into Compare, but any SLIMFORP model that uses a Dirfor file structure can be adapted for use with the Compare program.
The key to the Dirfor file structure is the DIRFOR.CRD file that is found in almost every SLIMFORP model (in LIFT, this is called DIRFOR.DAT). Those of you who work with LIFT or SLIMFORP already are familiar with this file, so it will not be described here in complete detail. However, there is a subtle difference in the format of the LIFT and SLIMFORP formats of this file. The Compare program works with the LIFT format as is, but minor changes must be made to the SLIMFORP versions.
daf\DIRHIS,
TOTAL NUMBER OF RECORDS
3064 /* = 1 + 22*67 + 5*25 + 10*26 + 2*67 +10*67 + 1*400
NUMBER OF RECORDS PRECEDING EACH BLOCK (IGN)
1 1475 1600 1860 1994 2664 3064
BLOCK 1 SERIES 22 SECTOR 67 IO LEVEL DATA
The DIRFOR.CRD for the Japanese model will be used in the example discussion below. The first change that needs to be made to the DIRFOR.CRD is in the section describing the blocks of the DIRFOR file. In the usual SLIMFORP format, these lines are as in the box below. The disadvantage of this traditional format is that, each time that the sector numbering or number of series in each block changes, these numbers must be hand edited, and new starting record numbers for each block must be calculated. In the LIFT format, these same lines would be written as follows:
daf\\DIRHIS,
6 blocks
Sectors in block 67 25 26 67 67 400
Number of series 22 5 10 2 10 1
BLOCK 1 SERIES 22 SECTOR 67 IO LEVEL DATA
In this format, the number of blocks is given in the first line, in the format (I2), and the number of sectors and number of series in each block are given in the following two lines, in the format (16X,12I4). The LIFT version of Mkdirfor will calculate the starting record numbers of each block automatically, based on these data, and Compare does the same.
BLOCK 1 SERIES 22 SECTOR 67 IO LEVEL DATA
SERIES 1 RDFIL 1 RPOINT 1 CENTRAL GOVERNMENT
IHIS 1history\CEN5584.HIS,
SERIES 2 1 2 LOCAL GOVERNMENT
IHIS 1history\LOC5584.HIS,
SERIES 3 1 3 WATER & SANITATION
IHIS 1history\WAS5584.HIS,
The next difference is that each series in the new format has its own mnemonic, by which it can be referred to in making tables. The traditional DIRFOR series format is displayed in the box below. To change this to the new format, you need only to add mnemonics of up to four characters, starting in column 32:
BLOCK 1 SERIES 22 SECTOR 67 IO LEVEL DATA
SERIES 1 RDFIL 1 RPOINT 1 CEN CENTRAL GOVERNMENT
IHIS 1history\CEN5584.HIS,
SERIES 2 1 2 LOC LOCAL GOVERNMENT
IHIS 1history\LOC5584.HIS,
SERIES 3 1 3 WAS WATER & SANITATION
IHIS 1history\WAS5584.HIS,
Once this is done, Compare can read the SLIMFORP file, using mnemonics such as cen1, loc21, etc. During the interactive running of the program, if you specify file type ‘d’ for Dirfor, you also will be asked to give the path of the DIRFOR.DAT file. You might want to keep a copy in the traditional format as DIRFOR.CRD and a copy in the new format as DIRFOR.DAT. Then you can use DIRFOR.DAT when running Compare.
